SC2Bot
A Deep Reinforcement Learning Model that Plays StarCraft II Minigames

SC2Bot
SC2Bot is a deep reinforcement learning agent that plays StarCraft II minigames: the Move To Beacon game and the Defeat Roaches game, both of which are provided as part of Deepmind’s PySC2 package. SC2Bot uses PySC2’s API to read data from StarCraft II, and the RL models are written in PyTorch.
The model learned how to play the Move To Beacon game over 10000 episodes of training, and then learned how to play the Defeat Roaches game over 10000 episodes of training after receiving transfer learning from the Move To Beacon task.
Check out the the SC2Bot github page here.
Scroll down for more details!
StarCraft II: A Quick Introduction
Starcraft II is a popular real time strategy video game in which players collect resources, build buildings, and create armies of units. In a 1v1 setting the game is won when one player has destroyed all of the other players’ buildings. Starcraft II can be thought of as a form of high-speed chess, where moves are performed in real time and players utilize both strategy and speed of action to win.
As a reinforcement learning problem, Starcraft II presents a combination of challenges that is not typically found in other traditional game-based reinforcement learning problems:
- Multi-Agent Interaction
- Imperfect Knowledge
- Delayed Credit Assignment
- ‘Continuous’ Environment
- Massive State-Action Space
The most well known way of overcoming these difficulties is to use an extremely high amount of computing power (e.g., see Deepmind’s Alphastar1). But given limited resources, what are some other ways we might be able to train an agent within a reasonable amount of time?
Reinforcement Learning Techniques
Deep Q-Learning
The agent is trained with a deep-Q network, which is essentially a neural network that uses the Q-learning algorithm.
Experience Replay
Experience replay is a technique developed as part of one of the original DQN network algorithms2. While interacting with the environment (StarCraft II in this case), our agent stores transition tuples of (s, a, r, s’). During training, the agent randomly samples a minibatch of these transitions (randomly because this avoids the problem of correlation between consecutive samples).
Double DQns
Q-learning can lead to an overestimation of action-values. To correct for this we use double DQNs. With this technique, our model contains two DQN networks. During training, when we select an action, one network (the online network) is updated based on the Q value of the other target network, which is held stationary (called the target network). Every so often, the target network overwrites its own weights with the weights of the online network. The idea here is that we allow our DQN to converge to a stationary target, rather than a target that changes as we update.
Transfer Learning
Transfer learning is a common technique used in deep learning, and since our DQNs are deep learning models, transfer learning can be applied naturally between tasks that use networks in the same way. In our case, the two tasks are the Move To Beacon task, and the Defeat Roaches task.
Experiments
Neural network architecture
The network architecture for SC2Bot is fairly simple: Three 2D convolutional layers with relu activations and without any fully connected layers at the end. Using fully connected layers would have been nice, but they were far too computationally expensive to train given my limited resources.

The network takes as input 32 by 32 grid of the ‘unit owner’ feature space provided by PySC2. This feature space assigns an owner to every point on the screen, so if there is an enemy unit at point (15, 18), for example, then in the grid, point (15, 18) would be given to the network as a 2. The output of the network is a point on the 32 by 32 grid, which denotes the place on the screen the agent should click to move its unit(s).
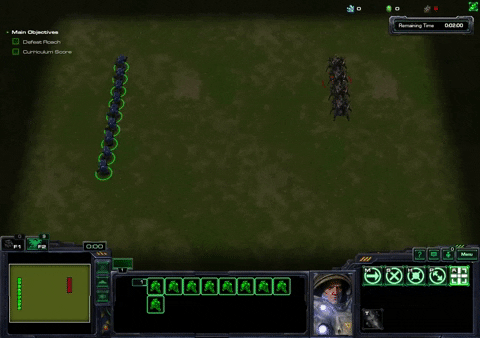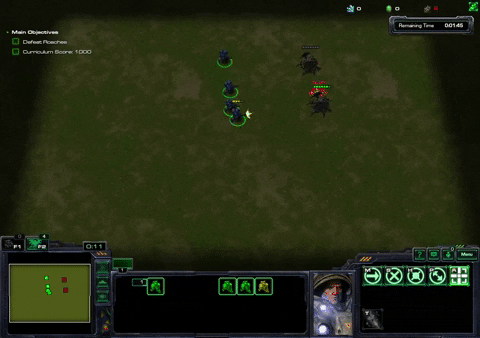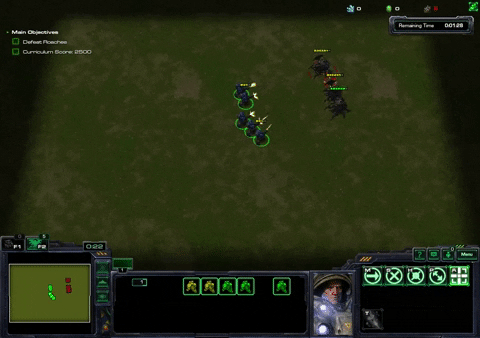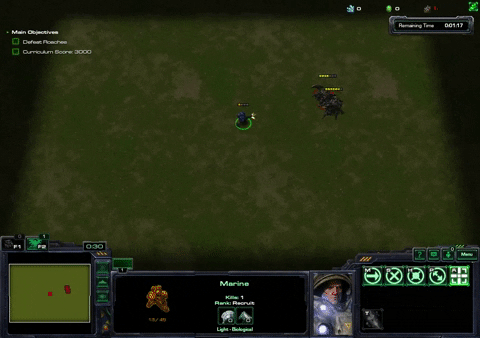
Move To Beacon Task
In the Move To Beacon task, the agent controls a single marine. A green beacon is spawned randomly on the map and the goal of the game is for the marine to move to the beacon. Every time the marine touches the beacon, the agent is awarded one point and the becaon spawns randomly at another location on the map. The agent is restricted to an action space of only allowing it to move to any point on the map, discretized into a 32x32 grid.
Defeat Roaches Task
In the Defeat Roaches Task, the agent controls an army of 8 marines that are spawned randomly on the map and 4 roaches are spawned randomly opposite them. Defeating the roaches spawns 5 new marines and 4 new roaches. The agent is rewarded for defeating roaches and penalized for time passing by and for attacking it’s own units (so that the agent doesn’t use a strategy of attacking its own units to minimize the amount of time passing by)
For both tasks, I trained agents independently on each task, but also trained a third agent on the Defeat Roaches task. This third agent’s network inherited its weights from the trained Move To Beacon agent before training. Ther results of all three agents are shown below.
Results
The agent trained on the Move To Beacon task was able to successfully learn how to optimally complete the task while the agent trained on the Roaches task with transfer learning from the Beacon task was able to learn a strong strategy for playing the Defeat Roaches minigame. Curiously, even after over 10000 episodes of training, the agent that did not receive any transfer learning was still not able to learn any consistent strategy for beating the Defeat Roaches game.
For a more detailed numerical analysis of the results, see my writeup.
Computational Requirements
Even though the DQN used by the agents is simple, and the minigames lack complexity, it still takes a nontrivial amount of computation power to train the agents. For reference, on my personal copmuter that has an Nvidia 8GB RTX 2070, it took about 10 hours to run 10000 episodes and train a network on those episodes.
To accelerate the training process, I used Google Cloud to train instances.
__
Acknowledgements
SC2Bot was a project completed as part of Tuft’s Comp 150-06 Reinforcement Learning class taught by Jivko Sinapov. Thanks Jivko and Gyan!